Milestone Report
Summary of Completed Work
We planned out the code design of the project including the different classes and files we would need. Then, we set up a project repository which imports the glm and OpenGL libraries and uses CMake for compilation. Next, we implemented a simple renderer with OpenGL that orthographically projects the particles onto a 2d plane. We integrated this rendering layer with a working sequential simulator supporting baseline features including position based density constraints and collision constraints, Jacobi iteration for updating particle positions, XSPH viscosity post processing, and surface tension correction. In our current implementation, we are able to load a scene file, step the sequential simulator on it, and draw the current state of the particles. A demo of our simulator on a simple scene with 10k particles is shown below. We also started implementing a parallel version of the simulator which involved writing CUDA kernels for the position and constraint updates.
Goals and Deliverables:
We believe that we are on track to complete all of the baseline goals and deliverables in our initial proposal as well as the stretch goals of surface tension correction and vorticity confinement. We’re ahead of schedule in terms of the simulation features we’re able to support as we finished the baseline goals of the density and collision constraints, Jacobi iteration, XSPH viscosity, and the stretch goal of surface tension correction. We’re slightly behind schedule in terms of integrating the parallel CUDA kernels and implementing parallel counting sort within our simulator. We’re also behind schedule for rendering as we only support 2D particles currently. The main stretch goal we’re still aiming for is implementing realistic rendering following the pipeline described in Interactive SPH Simulation and Rendering on the GPU. Our new baseline goals are to implement:
- Position-based density constraints and collision constraints
- Parallelized Jacobi iteration for updating particle positions (with CUDA kernels)
- Efficient neighbor computation using parallel counting sort (with CUDA kernels)
- Parallelization of particle and constraint updates (with CUDA kernels)
- XSPH viscosity post-processing for coherent motion
- Surface tension correction to reduce particle clustering
- Vorticity confinement to reduce numerical damping
- 3D Particle rendering using OpenGL
- Benchmarking of parallel vs. sequential versions on GPU vs. CPU
- Realistic rendering by implementing the GPU voxel rendering pipeline from Interactive SPH Simulation and Rendering on the GPU with CUDA kernels and GLSL shaders
- Extend the neighbor computation to use parallel radix sort (with CUDA) following the work of Fast Fixed-Radius Nearest Neighbors
Preliminary Results
Screenshots of our simulation:
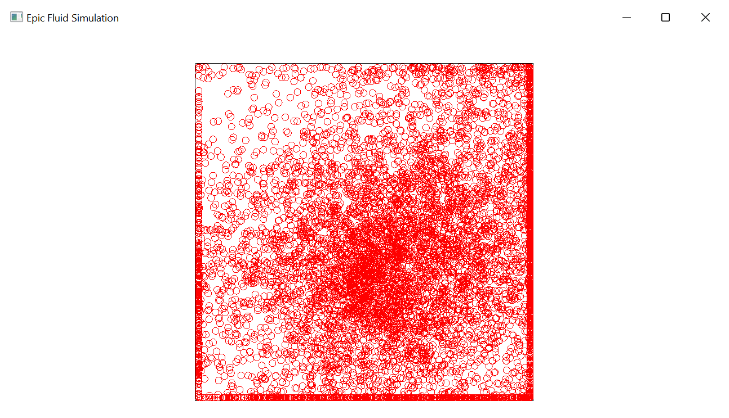
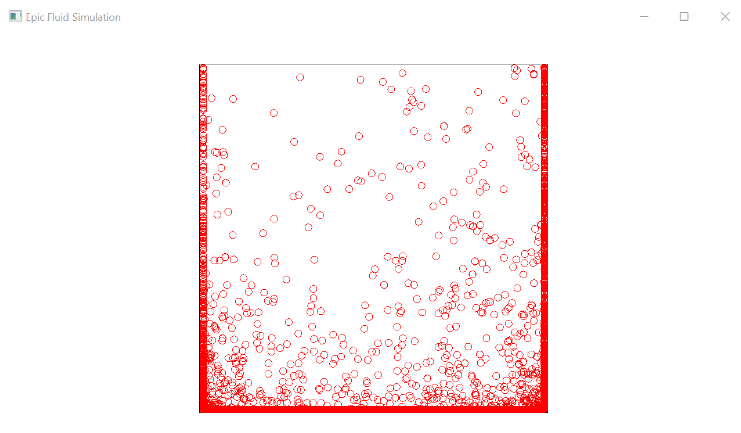
Potential Issues
The main issues we are concerned with are implementing a sufficient rendering layer so that we can at least render 3D particles and we are hoping to be able to implement more realistic rendering. We are planning on devoting more time towards this as we finish integrating the parallel simulator so that we can have a better demo. Another issue we are working on is tuning the hyperparameters of the physical simulation. We are largely following the hyperparameters listed in the main position-based fluids paper, but we’ve run into some unexpected behavior with some of them which we’ve had to tweak.
Updated Schedule
| Week | Todo |
|---|---|
| 11/10-11/16 | Discuss and fully understand the algorithm. Plan out code design for sequential and parallel versions of simulator. Complete implementation of sequential version with density and collision constraints with no rendering. |
| 11/17-11/23 | Write CUDA kernels for parallelized Jacobi iteration and particle and constraint updates. Begin implementation of rendering with OpenGL. |
| 11/24-11/30 | Produce first preliminary demo. Add XSPH viscosity post-processing. Finish intermediate milestone report. Implement surface tension correction. |
| 12/1-12/4 | Finish implementing 3D particle rendering using OpenGL (Lawrence). Begin extension of efficient neighbor computation with parallel counting sort (Konwoo). Implement vorticity confinement (Konwoo). |
| 12/5-12/7 | Finish parallelization of efficient neighbor computation (Konwoo). Integrate parallel code and CUDA kernels together (Lawrence). Produce a demo with all of our new features (Lawrence). |
| 12/8-12/11 | Begin benchmarking performance (Konwoo + Lawrence). Begin implementing GPU voxel rendering pipeline (Konwoo) and shaders (Lawrence). |
| 12/12-12/14 | Finish GPU rendering pipeline and shaders (Konwoo + Lawrence). Finish benchmarking and demo for presentation (Konwoo + Lawrence). If time permits, extend neighbor computation to use parallel radix sort (Lawrence). |
| 12/15-12/18 | Clean up code for submission (Konwoo + Lawrence). Prepare final report and poster (Konwoo + Lawrence). |